OCR処理がされていないPDFやWebサイトの画像データからは、当然ながらテキストとしてコピーはできません。どうしても入力が必要な際は、画像を見ながら手入力したり、長い文字列なら場合によっては一旦紙に書き落としてそれをキーボードでタイピングする方もいらっしゃるかもしれません。いずれにしても非効率で認知負荷も大きいタスクが発生します。
この課題を丁度良く解決できるという方法がありまして、Microsoft PowerToysのText Extractorを使えば画像からテキストデータを抽出できます。前準備としてMicrosoft StoreからMicrosoft PowerToysをインストールします。
Microsoft PowerToys
Microsoft PowerToysはWindowsの拡張機能で、インストールと設定により標準では搭載されていない機能を使うことができます。色々と便利な機能があるためブログでもまた別途ご紹介するかもしれません。
PowerToysをインストール後、WindowsからPowerToysの設定画面を立ち上げ、以下の機能を有効にします。
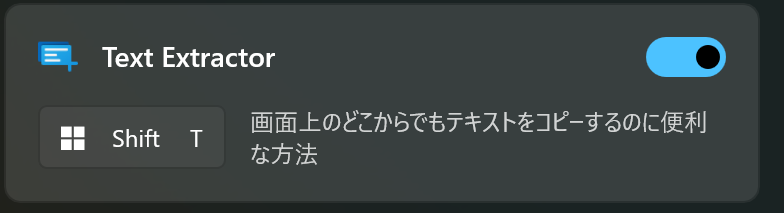
有効にした後で、Windowsキー + Shiftキー + Tと押すと画面を切り取るような状態となり、テキストデータを抽出したい画像の領域をドラッグします。例えば以下の国税庁サイト確定申告書作成コーナーの表示は画像データであるため、ドラッグしてもコピーできませんが、この機能を使ってCtrl+Vによりペーストすると、「国税庁確定申告書等作成コーナー令和 6 年分」というテキストを貼り付けられます。

紙をスキャンしたPDFに対しても表示がある程度明瞭であれば使用可能です。扱うデータがOCR処理された画像ばかりなら良いのですが、実務ではそうでない手ごわいデータに向き合わなければならない場面も多々あるかと思います。そんな時にはぜひお試しください。

